Breakthrough Innovations
Revolutionary training methodology combining trajectory-centric learning with dual reward optimization
Experience Multi-Step Reasoning
Watch Datarus solve complex data analysis problems with human-like iterative debugging and self-correction
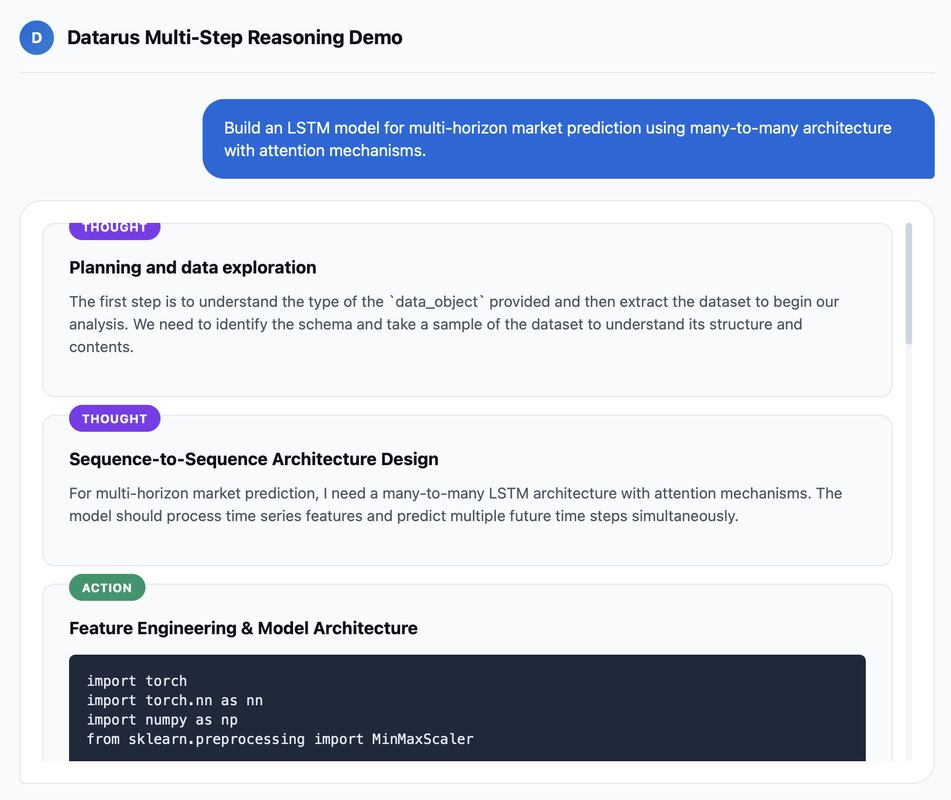
Iterative Refinement
Watch real-time error correction and hypothesis revision
AHA Moments
Observe breakthrough insights in complex problem-solving
Live Execution
See code generation, execution, and analysis in action
Excellent Performance & Efficiency
Outperforming 32B+ models while using significantly fewer tokens
Token Efficiency Revolution
While Phi-4-reasoning explodes from 2,160 to 20,400 tokens (945% increase) on hard problems, Datarus maintains consistent efficiency with only modest increases, delivering 18-49% token reduction across all difficulty levels without sacrificing accuracy.
Performance Visualizations
Visual comparisons demonstrating Datarus's superior efficiency and performance
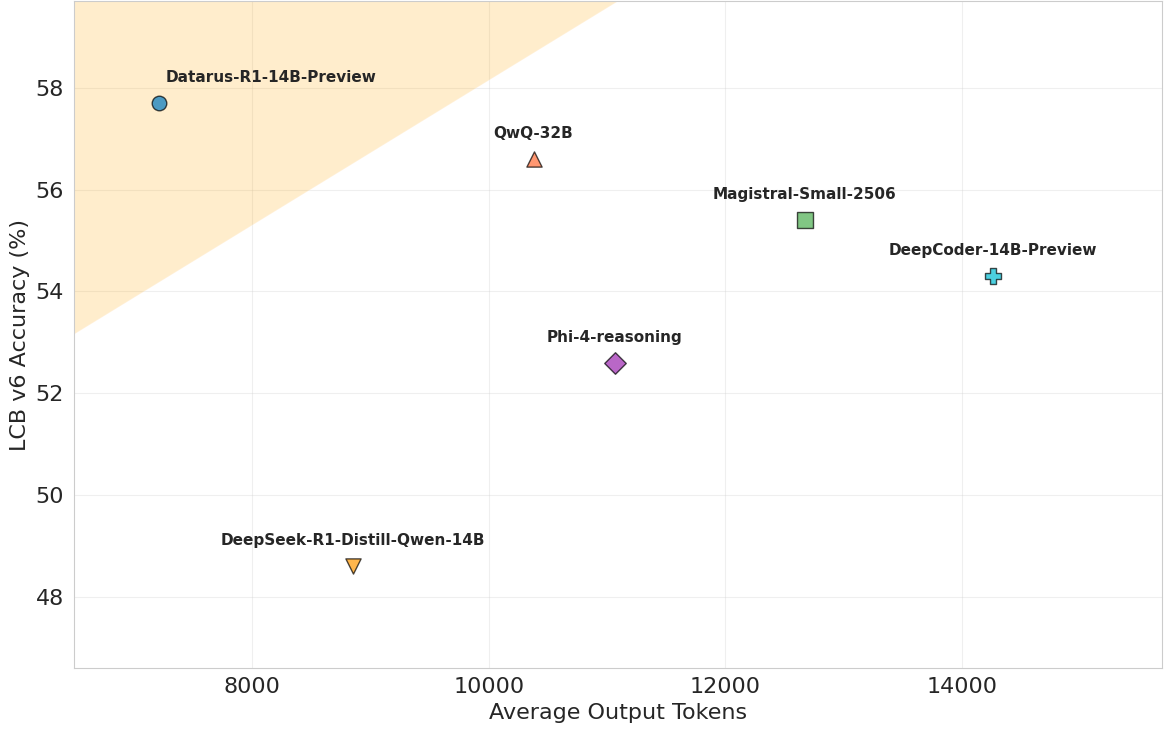
LiveCodeBench v6 Performance vs Efficiency
Achieving top-tier performance on LiveCodeBench v6 while maintaining exceptional token efficiency compared to competing models
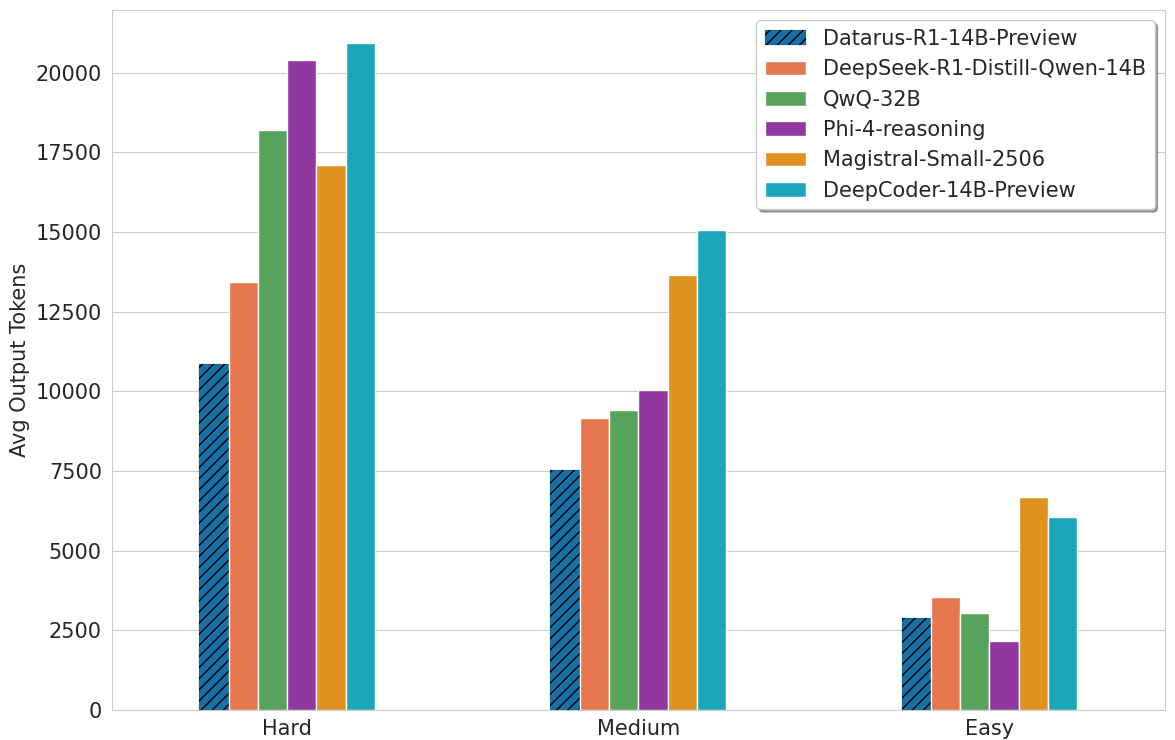
Token Efficiency Across Problem Difficulty
Datarus generates significantly fewer output tokens even when dealing with hard problems, maintaining efficiency where other models explode in token usage
Get Started with Datarus
Open-weights model available for research and commercial use